Intro code examples
Overview
Teaching: 30 min
Exercises: 20 minQuestions
What is the difference between serial and parallel code?
How do CPU and GPU programs differ?
What tools and programming models are used for HPC development?
Objectives
Understand the structure of CPU and GPU code examples.
Identify differences between serial, multi-threaded, and GPU-accelerated code.
Recognize common programming models like OpenMP, MPI, and CUDA.
Appreciate performance trade-offs and profiling basics.
Motivation for HPC Coding
Most users begin with simple serial code, which runs sequentially on one processor. However, for problems involving large data sets, high resolution simulations, or time-critical tasks, serial execution quickly becomes inefficient.
Parallel programming allows us to split work across multiple CPUs or even GPUs. High-Performance Computing (HPC) relies on this concept to solve problems faster. We can visualise this by looking at an example of finding the period for light curves. The visualisation of this example is given below:
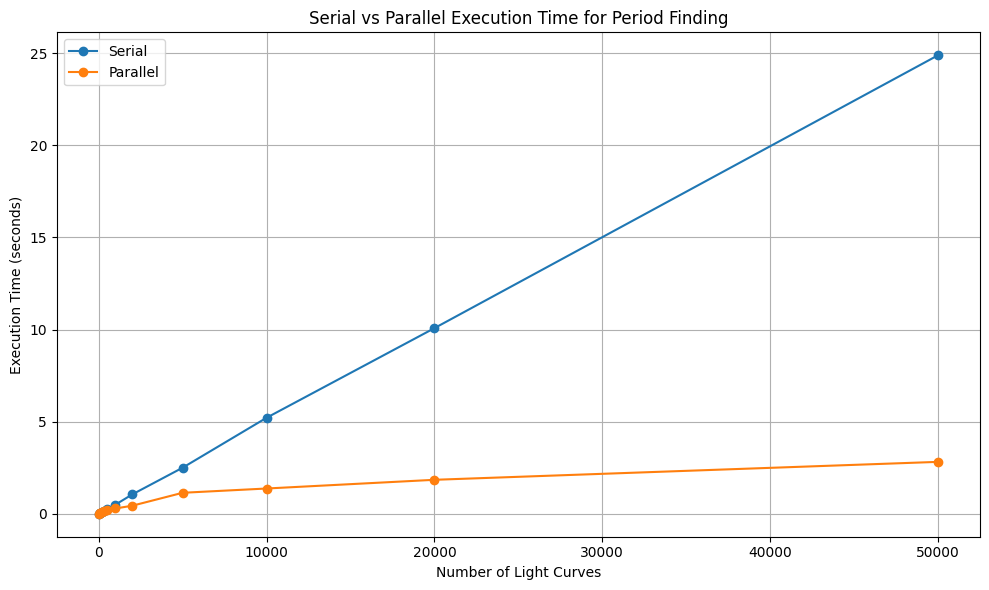
Serial Code Example (CPU)
Introduction to NumPy
Before diving into parallel computing or GPU acceleration, it’s important to understand how performance can already be improved significantly on a CPU using efficient libraries.
- One of the most widely used tools for this in Python is
NumPy. NumPy provides a fast and memory-efficient way to handle large numerical datasets using multi-dimensional arrays and vectorized operations. - While regular Python lists are flexible, they are not optimized for heavy numerical tasks. Looping through data element by element can quickly become a bottleneck as the problem size grows.
- NumPy solves this problem by providing a powerful N-dimensional array object and tools for performing operations on these arrays efficiently.
- Under the hood, NumPy uses optimized C code, so operations are much faster than using standard Python loops.
- NumPy also supports vectorized operations, which means you can apply functions to entire arrays without writing explicit loops. This not only improves performance but also leads to cleaner and more readable code.
- Using NumPy on the CPU is often the first step toward writing efficient scientific code.
- It’s a strong foundation before we move on to parallel computing or GPU acceleration. Now, we’ll see an example of how a simple numerical operation is implemented using NumPy on a single CPU core.
Example: Summing the elements of a large array using Serial Computation
import numpy as np
import time
array = np.random.rand(10**7)
start = time.time()
total = np.sum(array)
end = time.time()
print(f"Sum: {total}, Time taken: {end - start:.4f} seconds")
Exercise:
Modify the above to use a manual loop with
forinstead ofnp.sum, and compare the performance.
Solution
Replace
np.sum(array)with a manual loop usingfor.
Note: This will be much slower due to Python’s loop overhead.import numpy as np import time array = np.random.rand(10**7) start = time.time() total = 0.0 for value in array: total += value end = time.time() print(f"Sum: {total}, Time taken: {end - start:.4f} seconds")This gives you a baseline for how optimized
np.sumis compared to native Python loops.
Reference:
Parallel CPU Programming
Introduction to OpenMP and MPI
Parallel programming on CPUs is primarily achieved through two widely-used models:
OpenMP (Open Multi-Processing)
OpenMP is used for shared-memory parallelism. It enables multi-threading where each thread has access to the same memory space. It is ideal for multicore processors on a single node.
OpenMP was first introduced in October 1997 as a collaborative effort between hardware vendors, software developers, and academia. The goal was to standardize a simple, portable API for shared-memory parallel programming in C, C++, and Fortran. Over time, OpenMP has evolved to support nested parallelism, Single Instruction Multiple Data (vectorization), and offloading to GPUs, while remaining easy to integrate into existing code through compiler directives.
OpenMP is now maintained by the OpenMP Architecture Review Board, which includes organizations like Arm, AMD, IBM, Intel, Cray, HP, Fujitsu, Nvidia, NEC, Red Hat, Texas Instruments, and Oracle Corporation. OpenMP allows you to parallelize loops in C/C++ or Fortran using compiler directives.
Terminology
Nested Parallelism
- Nested parallelism occurs when a parallel task itself spawns additional parallel tasks. For example, imagine a program where each thread is responsible for a different data block, and within each block, more threads are launched to handle sub-tasks. This is useful when dealing with hierarchical or recursive algorithms but must be managed carefully to avoid performance penalties due to thread overhead.
Single Instruction, Multiple Data (SIMD) – Vectorization
- SIMD is a form of data-level parallelism where the same instruction operates on multiple data elements simultaneously. For instance, instead of adding two numbers at a time, SIMD allows processors to add pairs of numbers in parallel using wide registers (like 128-bit or 256-bit). Vectorized operations using NumPy or compiler intrinsics take advantage of this under the hood to speed up loops.
Offloading to GPUs
- Offloading refers to transferring compute-intensive tasks from the CPU to the GPU, which is optimized for parallel processing. This is particularly effective for operations that can be executed simultaneously on thousands of threads, like matrix multiplications in deep learning or simulations in scientific computing. Tools like CUDA, OpenCL, or libraries like CuPy and PyTorch help achieve this in Python.
Example: Running a loop in parallel using OpenMP
#include <omp.h>
#pragma omp parallel for
for (int i = 0; i < N; i++) {
a[i] = b[i] + c[i];
}
Since C programming is not a prerequisite for this workshop, let’s break down the parallel loop code in detail.
Requirements:
- Add
#include <omp.h>to your code - Compile with
-fopenmpflag
Before we look at the explanation of the C code, we will first look at the Python Equivalent of this code
Python Equivalent of the Code Logic
def add_arrays(b, c):
"""
Takes two lists `b` and `c`, adds corresponding elements,
and returns the resulting list `a` where a[i] = b[i] + c[i].
"""
# Make sure both lists are the same length
assert len(b) == len(c), "Input arrays must be the same length"
# Create an output list of the same size
a = [0.0 for _ in range(len(b))]
# Loop through and compute a[i] = b[i] + c[i]
for i in range(len(b)):
a[i] = b[i] + c[i]
return a
# Example usage
N = 100000
b = [i * 0.1 for i in range(N)]
c = [i * 0.2 for i in range(N)]
a = add_arrays(b, c)
# Print first few values to verify
print(a[:10])
Explanation of the C code
#include <omp.h>: Includes the OpenMP API header needed for all OpenMP functions and directives.#pragma omp parallel for: A compiler directive that tells the compiler to parallelize theforloop that follows.- The
forloop itself performs element-wise addition of two arrays (bandc), storing the result in arraya.How OpenMP Executes This
- OpenMP detects available CPU cores (e.g., 4 or 8).
- It splits the loop into chunks — one for each thread.
- Each core runs its chunk simultaneously (in parallel).
- The threads synchronize automatically once all work is done.
Output
- The output is stored in array
a, which will contain the sum of corresponding elements from arraysbandc. The execution is faster than running the loop sequentially.Real-World Analogy
Suppose you need to send 100 emails:
- Without OpenMP: One person sends all 100 emails one by one.
- With OpenMP: 4 people each send 25 emails at the same time — finishing in a quarter of the time.
Exercise: Parallelization Challenge
Consider this loop:
for (int i = 1; i < N; i++) { a[i] = a[i-1] + b[i]; }Can this be parallelized with OpenMP? Why or why not?
Solution
No, this cannot be safely parallelized because each iteration depends on the result of the previous iteration (
a[i-1]).OpenMP requires loop iterations to be independent for parallel execution. Here, since each
a[i]relies ona[i-1], the loop has a sequential dependency, also known as a loop-carried dependency.This prevents naive parallelization with OpenMP’s
#pragma omp parallel for.However, this type of problem can be parallelized using more advanced techniques like a parallel prefix sum (scan) algorithm, which restructures the computation to allow parallel execution in logarithmic steps instead of linear.
MPI (Message Passing Interface)
MPI is used for distributed-memory parallelism. Processes run on separate memory spaces (often on different nodes) and communicate via message passing. It is suitable for large-scale HPC clusters.
MPI emerged earlier, in the early 1990s, as the need for a standardized message-passing interface became clear in the growing field of distributed-memory computing. Before MPI, various parallel systems used their own vendor-specific libraries, making code difficult to port across machines.
In June 1994, the first official MPI standard (MPI-1) was published by the MPI Forum, a collective of academic institutions, government labs, and industry partners. Since then, MPI has become the de facto standard for scalable parallel computing across multiple nodes, and it continues to evolve with versions like MPI-2, MPI-3, MPI-4, and finally MPI-5 released on June 5 2025 which add support for features like parallel I/O and dynamic process management.
Example: Implementation of MPI using the mpi4py library in python
from mpi4py import MPI
comm = MPI.COMM_WORLD
rank = comm.Get_rank()
size = comm.Get_size()
data = rank ** 2
all_data = comm.gather(data, root=0)
if rank == 0:
print(all_data)
Explanation of the code
This example demonstrates a basic use of
mpi4pyto perform a gather operation using theMPI.COMM_WORLDcommunicator.Each process:
- Determines its rank (an integer from 0 to N-1, where N is the number of processes).
- Computes
rank ** 2(the square of its rank).- Uses
comm.gather()to send the result to the root process (rank 0).Only the root process gathers the data and prints the complete list.
Example Output (4 processes):
- Rank 0 computes
0² = 0- Rank 1 computes
1² = 1- Rank 2 computes
2² = 4- Rank 3 computes
3² = 9The root process (rank 0) gathers all results and prints:
[0, 1, 4, 9]
- Other ranks do not print anything.
This example illustrates point-to-root communication which is useful when one process needs to collect and process results from all workers.
Slurm Script to execute the code
#!/bin/bash
#SBATCH --job-name=mpi_hpc_ws
#SBATCH --output=mpi_%j.out
#SBATCH --error=mpi_%j.err
#SBATCH --partition=defaultq
#SBATCH --nodes=2
#SBATCH --ntasks=4
#SBATCH --time=00:10:00
#SBATCH --mem=16G
# Load required modules
module purge # Remove the list of pre loaded modules
module load Python/3.9.1
module list # List the modules
# Create a python virtual environment
python3 -m venv name_of_your_venv
# Activate your Python environment
source name_of_your_venv/bin/activate
# Run the MPI job
mpirun -np 4 python mpi_hpc_ws.py
Make sure your virtual environment has mpi4py installed and that your system has access to the OpenMPI runtime via mpirun. Adjust the number of nodes and tasks depending on the cluster policies.
Exercise:
Modify serial array summation using OpenMP (C) or
multiprocessing(Python).
References:
GPU Programming Concepts
GPUs, or Graphics Processing Units, are composed of thousands of lightweight processing cores that are optimized for handling multiple operations simultaneously. This parallel architecture makes them particularly effective for data-parallel problems, where the same operation is performed independently across large datasets such as matrix multiplications, vector operations, or image processing tasks.
Originally designed to accelerate the rendering of complex graphics and visual effects in computer games, GPUs are inherently well-suited for high-throughput computations involving large tensors and multidimensional arrays. Their architecture enables them to perform numerous arithmetic operations in parallel, which has made them increasingly valuable in scientific computing, deep learning, and simulations.
Even without explicit parallel programming, many modern libraries and frameworks (such as TensorFlow, PyTorch, and CuPy) can automatically leverage GPU acceleration to significantly improve performance. However, to fully exploit the computational power of GPUs, especially in high-performance computing (HPC) environments, explicit parallelization is often employed.
Introduction to CUDA
In HPC systems, CUDA (Compute Unified Device Architecture), a parallel computing platform and programming model developed by NVIDIA is the most widely used platform for GPU programming. CUDA allows developers to write highly parallel code that runs directly on the GPU, providing fine-grained control over memory usage, thread management, and performance optimization. It allows developers to harness the power of NVIDIA GPUs for general-purpose computing, known as GPGPU (General-Purpose computing on Graphics Processing Units).
A Brief History
- Introduced by NVIDIA in 2006, CUDA was the first platform to provide direct access to the GPU’s virtual instruction set and parallel computational elements.
- Before CUDA, GPUs were primarily used for rendering graphics, and general-purpose computations required indirect use through graphics APIs like OpenGL or DirectX.
- CUDA revolutionized scientific computing, deep learning, and high-performance computing (HPC) by enabling massive parallelism and accelerating workloads previously limited to CPUs.
How CUDA Works
CUDA allows developers to write C, C++, Fortran, and Python code that runs on the GPU.
- A CUDA program typically runs on both the CPU (host) and the GPU (device).
- Computational tasks (kernels) are written to execute in parallel across thousands of lightweight CUDA threads.
- These threads are organized hierarchically into:
- Grids of Blocks
- Blocks of Threads
- This can be visualised in the following form
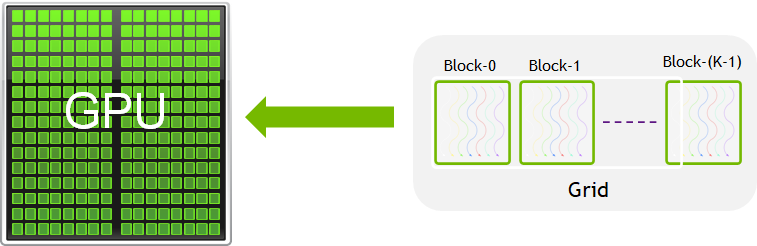
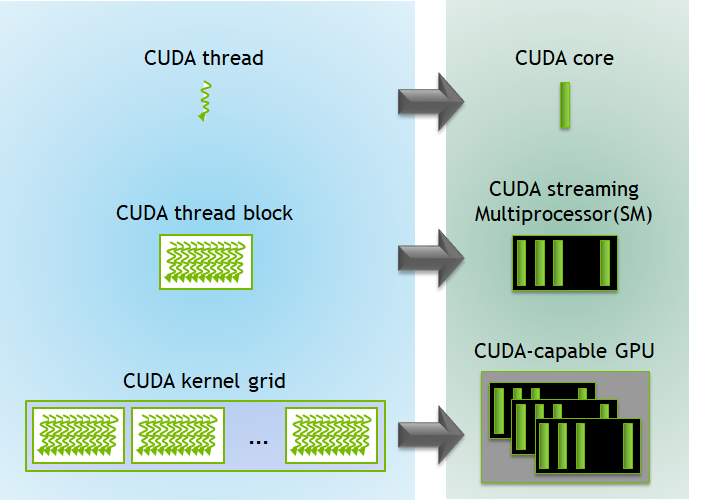
Figure Source:
Key Features
- Massive parallelism with thousands of concurrent threads
- Unified memory architecture for seamless CPU-GPU data access
- Built-in libraries for BLAS, FFT, random number generation, and more (e.g., cuBLAS, cuFFT, cuRAND)
- Tooling support including profilers, debuggers, and performance analyzers (e.g., Nsight, CUDA-GDB)
A CUDA program includes:
- Host code: Runs on the CPU, manages memory, and launches kernels.
- Device code (kernel): Runs on the GPU.
- Memory management: Host/device memory allocations and transfers.
To execute any CUDA program, there are three main steps:
- Copy the input data from host memory to device memory, also known as host-to-device transfer.
- Load the GPU program and execute, caching data on-chip for performance.
- Copy the results from device memory to host memory, also called device-to-host transfer.
Checking CUDA availability before running code
import cuda
if cuda.is_available():
print("CUDA is available!")
print(f"Detected GPU: {cuda.get_current_device().name}")
else:
print("CUDA is NOT available.")
High-Level Libraries for Portability
High-level libraries allow easier GPU programming in Python:
- Numba: JIT compiler for Python; supports GPU via
@cuda.jit - CuPy: NumPy-like API for NVIDIA GPUs
- Dask: Parallel computing with familiar APIs
Example: Add vectors utlising CUDA using the numba python library
from numba_cuda import cuda
import numpy as np
import time
@cuda.jit
def add_vectors(a, b, c):
i = cuda.grid(1)
if i < a.size:
c[i] = a[i] + b[i]
# Setup input arrays
N = 1_000_000
a = np.arange(N, dtype=np.float32)
b = np.arange(N, dtype=np.float32)
c = np.zeros_like(a)
# Copy arrays to device
d_a = cuda.to_device(a)
d_b = cuda.to_device(b)
d_c = cuda.device_array_like(a)
# Configure the kernel
threads_per_block = 256
blocks_per_grid = (N + threads_per_block - 1) // threads_per_block
# Launch the kernel
start = time.time()
add_vectors[blocks_per_grid, threads_per_block](d_a, d_b, d_c)
cuda.synchronize() # Wait for GPU to finish
gpu_time = time.time() - start
# Copy result back to host
d_c.copy_to_host(out=c)
# Verify results
print("First 5 results:", c[:5])
print("Time taken on GPU:", gpu_time, "seconds")
Slurm Script to execute the code
The following script can be used to submit a GPU-accelerated Python job (numba_cuda_test.py) using Slurm:
#!/bin/bash
#SBATCH --job-name=Numba_Cuda
#SBATCH --output=Numba_Cuda_%j.out
#SBATCH --error=Numba_Cuda_%j.err
#SBATCH --partition=gpu
#SBATCH --nodes=1
#SBATCH --ntasks-per-node=1
#SBATCH --cpus-per-task=4
#SBATCH --mem=16G
#SBATCH --gpus-per-node=1
#SBATCH --time=00:10:00
# --------- Load Environment ---------
module load Python/3.9.1
module load cuda/11.2
module list
# --------- Check whether the GPU is available ---------
from numba import cuda
print("CUDA Available:", cuda.is_available())
# Activate virtual environment
source 'name_of_venv'/bin/activate # Here name_of_venv refers to the name of your virtual environment without the quotes
# --------- Run the Python Script ---------
python numba_cuda_test.py
Make sure your virtual environment includes the numba-cuda python library to access the GPU.
Exercise:
Write a Numba or CuPy version of vector addition and compare speed with NumPy.
References:
CPU vs GPU Architecture
- CPUs: Few powerful cores, better for sequential tasks.
- GPUs: Many lightweight cores, ideal for parallel workloads.
Comparing CPU and GPU Approaches
| Feature | CPU (OpenMP/MPI) | GPU (CUDA) |
|---|---|---|
| Cores | Few (2–64) | Thousands (1024–10000+) |
| Memory | Shared / distributed | Device-local (needs transfer) |
| Programming | Easier to debug | Requires more setup |
| Performance | Good for logic-heavy tasks | Excellent for large, data-parallel problems |
Exercise:
Show which parts of the code execute on GPU vs CPU (host vs device). Read about concepts like memory copy and kernel launch from the CUDA C++ Programming Guide Chapter 5.
Reference: NVIDIA CUDA Samples
Summary
- Serial code is simple but doesn’t scale well.
- Use OpenMP and MPI for parallelism on CPUs.
- Use CUDA (or high-level wrappers like Numba/CuPy) for GPU programming.
- Always profile your code to understand performance.
- Choose your tool based on problem size, complexity, and hardware.
Key Points
Serial code is limited to a single thread of execution, while parallel code uses multiple cores or nodes.
OpenMP and MPI are popular for parallel CPU programming; CUDA is used for GPU programming.
High-level libraries like Numba and CuPy make GPU acceleration accessible from Python.